
An underbaked GPT-Codex-5.3-Spark review
Two days ago, OpenAI released GPT-5.3-Codex-Spark. I excitedly subscribed to ChatGPT Pro to try it, and now that I’ve been using it for two days, I have a fully comprehensive understanding of the model and am ready to pass judgement.
The speed of the model is incredible. Watching tokens fly by at breakneck speed, especially when it’s purely outputting tokens (as opposed to searching or using subagents, which doesn’t show up in the UI), is magical.
It’s also the first time I’ve seriously used the Codex Mac app or their CLI, both of which are on-par with what’s expected these days (and the Mac app has a nice way of seeing diffs, both from the current turn and the whole branch diff against main).
However, my experience with gpt-5.3-codex-spark is that it’s noticeably dumber. I was initially very impressed with a couple tasks, where it got the answer correct and very fast. But this graph very quickly felt true:
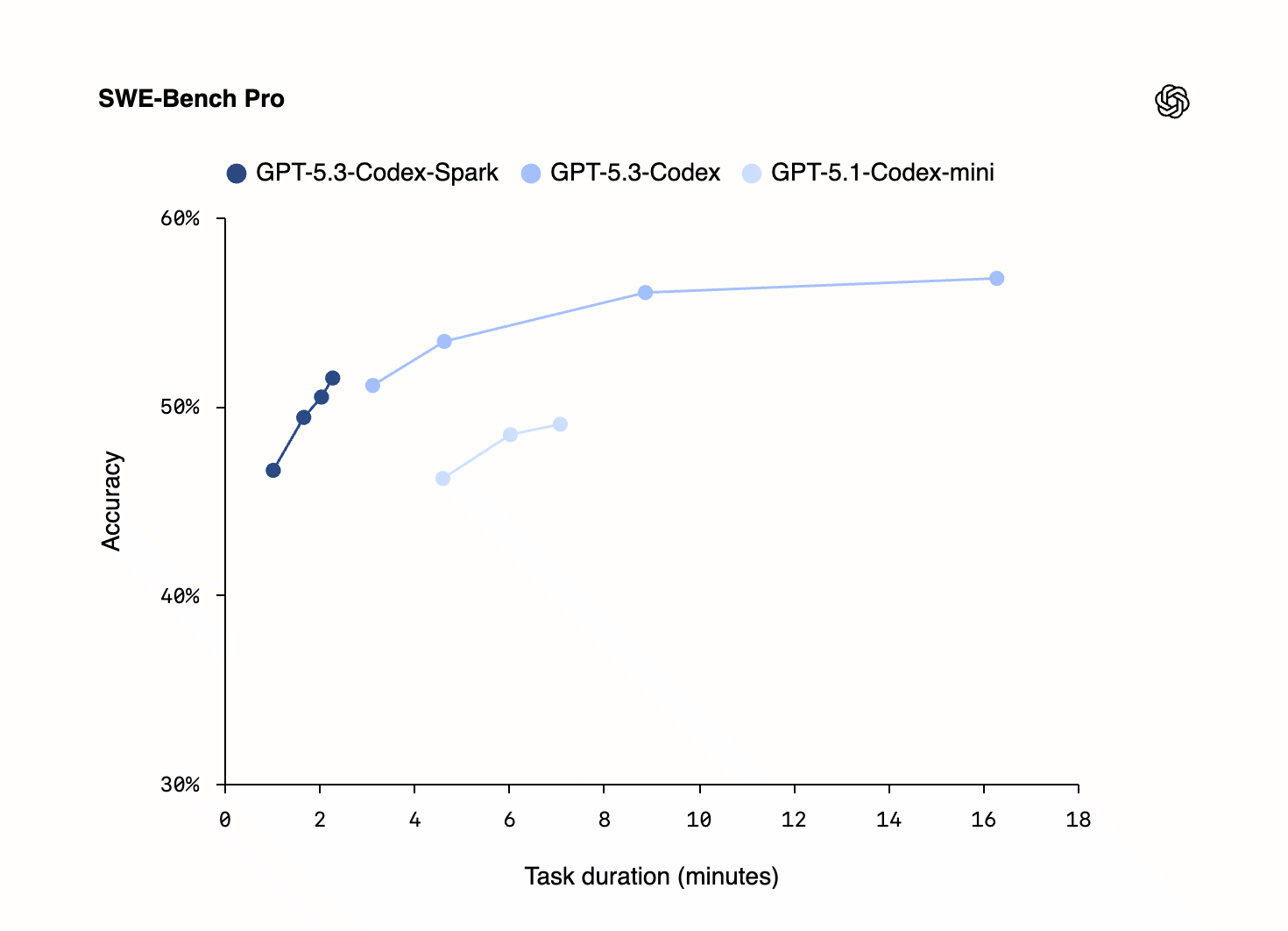 The graph shows that the
The graph shows that the extra-high version of Spark is on-par with the low version of the normal GPT-5.3-Codex. And I don’t really care about theoretical benchmarks, but in my experience, there were real investigations that GPT-5.3-Codex and Opus 4.6 could do while GPT-5.3-Codex-Spark couldn’t. Spark found plausible-but-incorrect results, which was unnerving.
The model feels a bit like a hyperactive child. It goes extremely quickly, bashes into a bunch of walls, isn’t the best at listening to instructions, and is wrong a bit more often than the slow, adult models.
The Codex models in general also don’t feel as good at UI work to me — the UI they produce often feels amateurish and unconsidered. Opus seems to have a much better sense of design, and better adherence to Figma screenshots. Spark is also not a vision model, which means I can’t ask it to iterate against UI using agent-browser.
Maybe back when Cursor released Composer (which they recently improved), I would have said that there’s a place for fast-but-slightly-dumber models. But I don’t think I believe that anymore.
The frontier models (Opus 4.6 and GPT-5.3-Codex) are so good that they side-step significant frustration. It doesn’t feel like a worthwhile tradeoff to go down a level in intelligence when you could just wait a bit longer for a response. Plus, a smarter model that can keep up with you probably saves significant time in back-and-forth overall.
I’m excited about what GPT-5.3-Codex-Spark could do as a subagent, for example in Amp. But as a main model, I think I’m back to Opus 4.6 for now.